About AIIC
The Artificial Intelligence and Innovation Center (AIIC) is a pioneering research and development hub dedicated to advancing artificial intelligence across multiple domains. Our mission is to foster innovation, empower researchers, and drive technological advancements that address real-world challenges.
Our Mission At AIIC, we are committed to harnessing the power of AI to improve lives, enhance industries, and contribute to scientific progress. We believe in ethical AI development, emphasizing inclusivity, transparency, and social responsibility in all our projects.
Who We Are AIIC is a dynamic collaboration of researchers, engineers, and industry professionals passionate about AI, data science, and video game development. Our team works at the intersection of technology and creativity, striving to push the boundaries of what AI can achieve.
What We Do
- Innovative AI Solutions: We develop AI-driven applications that improve decision-making, optimize processes, and enhance user experiences.
- Kurdish Language Digital Advancement: We are dedicated to ensuring the Kurdish language thrives in the digital era through natural language processing, machine translation, and voice recognition technologies.
- Video Game Development: AIIC explores game development, merging technology with storytelling to create immersive experiences for players worldwide.
- Education and Collaboration: We provide learning opportunities through workshops, internships, and training programs, empowering the next generation of AI innovators.
- Research and Publications: Our center actively contributes to the global AI community by publishing research findings, technical reports, and open-source resources.
Join Us Whether you’re a researcher, developer, student, or industry professional, AIIC welcomes collaboration and partnerships. Together, we can shape the future of AI, advance digital transformation, and make meaningful contributions to the world of technology.
Focus
The AIIC is dedicated to developing AI solutions that tackle global challenges in healthcare, business, and engineering. While driving innovation on a broad scale, we also prioritize the digital advancement of the Kurdish language, ensuring it thrives in the modern technological landscape. Additionally, we explore the dynamic field of video game development, creating immersive experiences that engage and inspire players worldwide.
Research Areas
The AIIC specializes in interdisciplinary research, addressing key sectors such as healthcare, business, and engineering. We develop tools ranging from predictive analytics and automation systems to intelligent software solutions. Additionally, we explore video game development, creating immersive gameplay experiences. A significant effort is also dedicated to the digital enhancement of the Kurdish language, with ongoing work in natural language processing, machine translation, and voice recognition to ensure its inclusion in the global digital landscape.
Education and Training
- The AIIC supports skill development through various programs, including workshops, training sessions, and internships.
- Programs are designed for students, researchers, and professionals seeking practical experience in AI, data science, and video game development.
- Participants gain access to modern tools and expert guidance to help them contribute to innovation across multiple fields.
Events and Highlights
- The AIIC will host conferences, guest lectures, and training sessions to promote collaboration and knowledge-sharing.
- Provides opportunities for networking, learning, and exploring advancements in AI research and technology.
- Offers a range of events, from beginner-friendly workshops to advanced technical seminars, catering to diverse levels of expertise.
Publications and Knowledge Hub
AIIC serves as a resource for knowledge and innovation by publishing its research findings, technical reports, and project outcomes. These contributions aim to advance the field of AI while making valuable information accessible to the broader community. Additionally, we provide open-source tools and datasets to support further research and development in both AI and video game development.
Staff
Research Assistant in Artificial Intelligence (AI)


Projects
GitHub
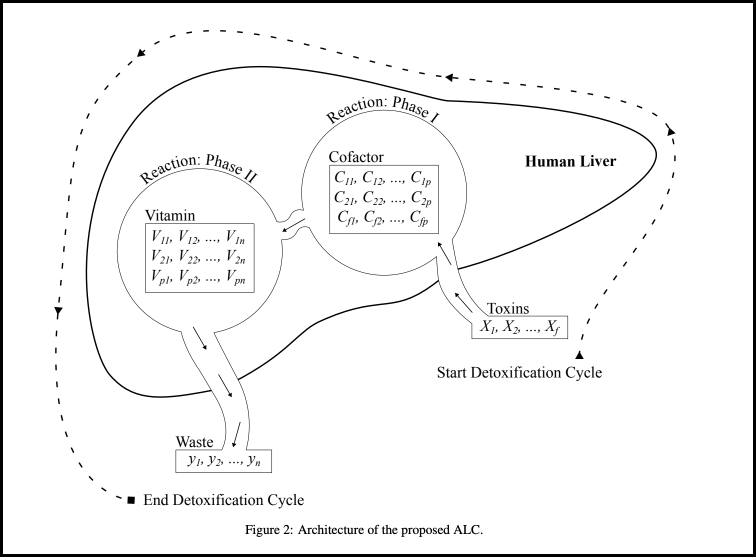
The Artificial Liver Classifier (ALC), inspired by liver detoxification, offers simplicity, speed, and reduced overfitting. Trained with the improved FOX algorithm, it achieved high accuracy, including 100% on Iris and 99.12% on Breast Cancer, highlighting the promise of biologically inspired machine learning models.
GitHub
Foxtsage, a hybrid optimizer combining FOX-TSA and SGD, improves neural network training by reducing loss mean by 42.03% and enhancing consistency over Adam. It also shows modest gains in accuracy, precision, recall, and F1-score but with a 330.87% increase in computational time, making it a robust alternative for optimization tasks.
[email protected]
Ratslayer is a Vampire Survivors-inspired game where you battle waves of enemies as a quirky hero in a cartoony world, featuring unique power-ups and fast-paced action.
[email protected]
Zingil is a language-based puzzle game that challenges players to solve linguistic riddles in an immersive world.
[email protected]
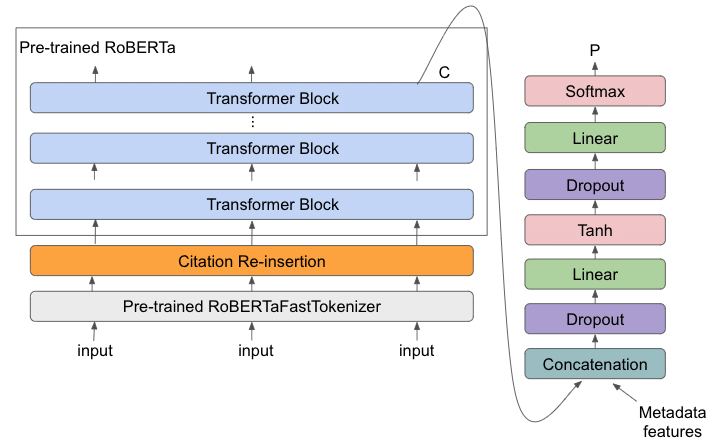
This is a fine-tuned version of abdulhade/RoBERTa-large-SizeCorpus_1B, designed for detecting and classifying Kurdish and English text. Leveraging a custom bilingual corpus, this model is effective in distinguishing between these languages and accurately identifying text segments.
[email protected]
This repository focuses on fine-tuning a Kurdish-English machine translation model using Hugging Face’s transformers library with MarianMT. The model is trained on a custom parallel corpus with a detailed pipeline that includes data preprocessing, bidirectional training, evaluation, and inference.
[email protected]
This is a fine-tuned version of abdulhade/RoBERTa-large-SizeCorpus_1B, designed for detecting and classifying Kurdish and English text. Leveraging a custom bilingual corpus, this model is effective in distinguishing between these languages and accurately identifying text segments.
[email protected]
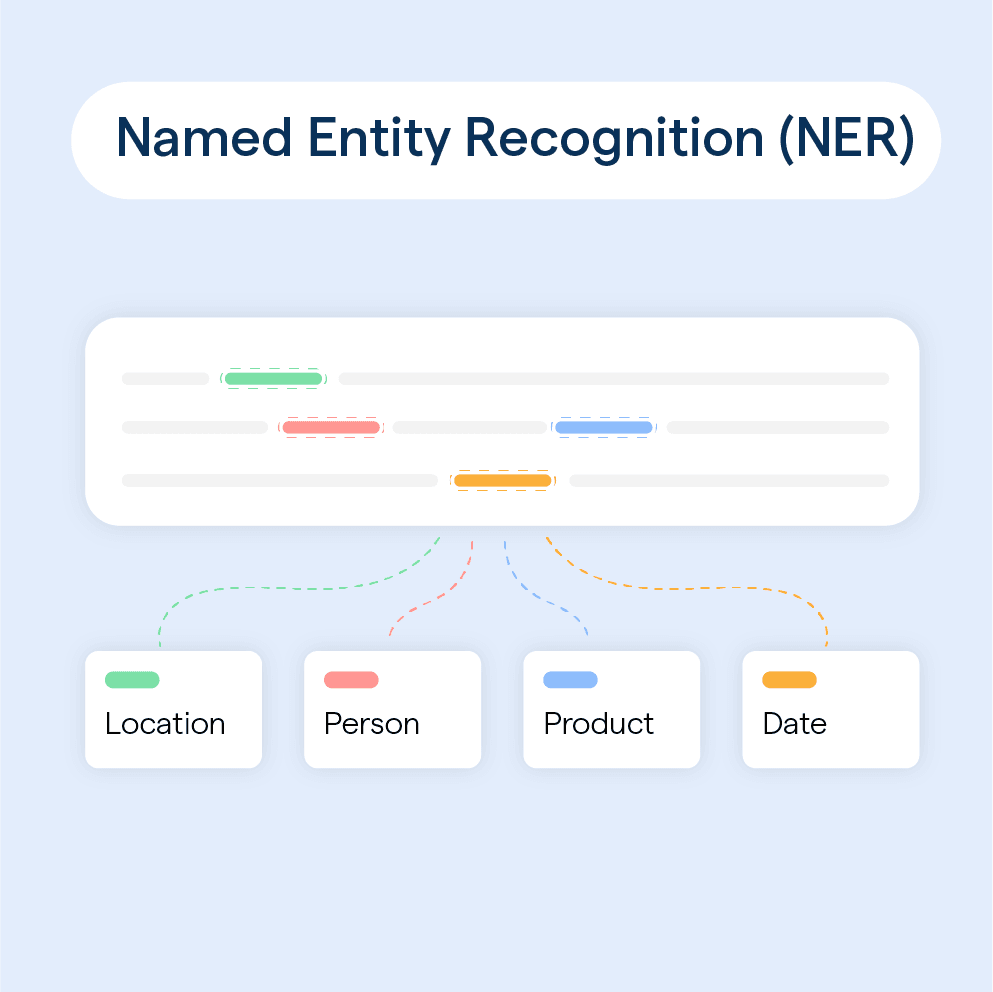
The project focuses on fine-tuning a pre-trained RoBERTa (Robustly Optimized BERT Pretraining Approach) model for Named Entity Recognition (NER) tasks. NER is a fundamental Natural Language Processing (NLP) task that involves identifying and classifying entities in text, such as names of people, organizations, locations, dates, and more.
Datasets
[email protected]
This dataset is designed for NLP tasks like sequence tagging and NER. It includes 1,472 sentences, 9,528 tokens, and 42 unique tags, making it ideal for training and evaluating NER models and token classification.
[email protected]
A collection of Central Kurdish (Sorani) text corpus with a size of 430 MB
Number of rows: 773,800
Get Involved
At AIIC, we believe that meaningful progress happens when ideas are shared and communities work together. This space is dedicated to anyone who wishes to connect with us whether you have a creative idea, a project proposal, a request for support, or simply a desire to collaborate. By bringing together diverse perspectives, we can co-create solutions that drive innovation, learning, and impact across different fields.
We invite you to share your thoughts, initiatives, and requests with us through the form below. Your contributions will help shape the future of AIIC’s projects and strengthen our commitment to collaboration and community-driven innovation.
Ready to get involved? Submit your idea or request using the form.
Submit From
Activities
Join AIIC in Shaping the Future!
- Explore collaboration opportunities
- Partner with us on groundbreaking AI projects
Contact Details:
- Email: [email protected]
- Location: 30m Avenue, University of Kurdistan Hewlêr, Opposite of the Main Reception Area